AI 기반 정보보호 R&D 데이터 챌린지 2018 예선전을 참여하고 작성한 보고서 입니다.
실제 대회에서 사용하였으며, 동적분석방법을 준비해갔으나 시간이 부족하다고 판단하여 정적분석으로 변경하였습니다.
git: https://github.com/epicarts/AI_challenge2018
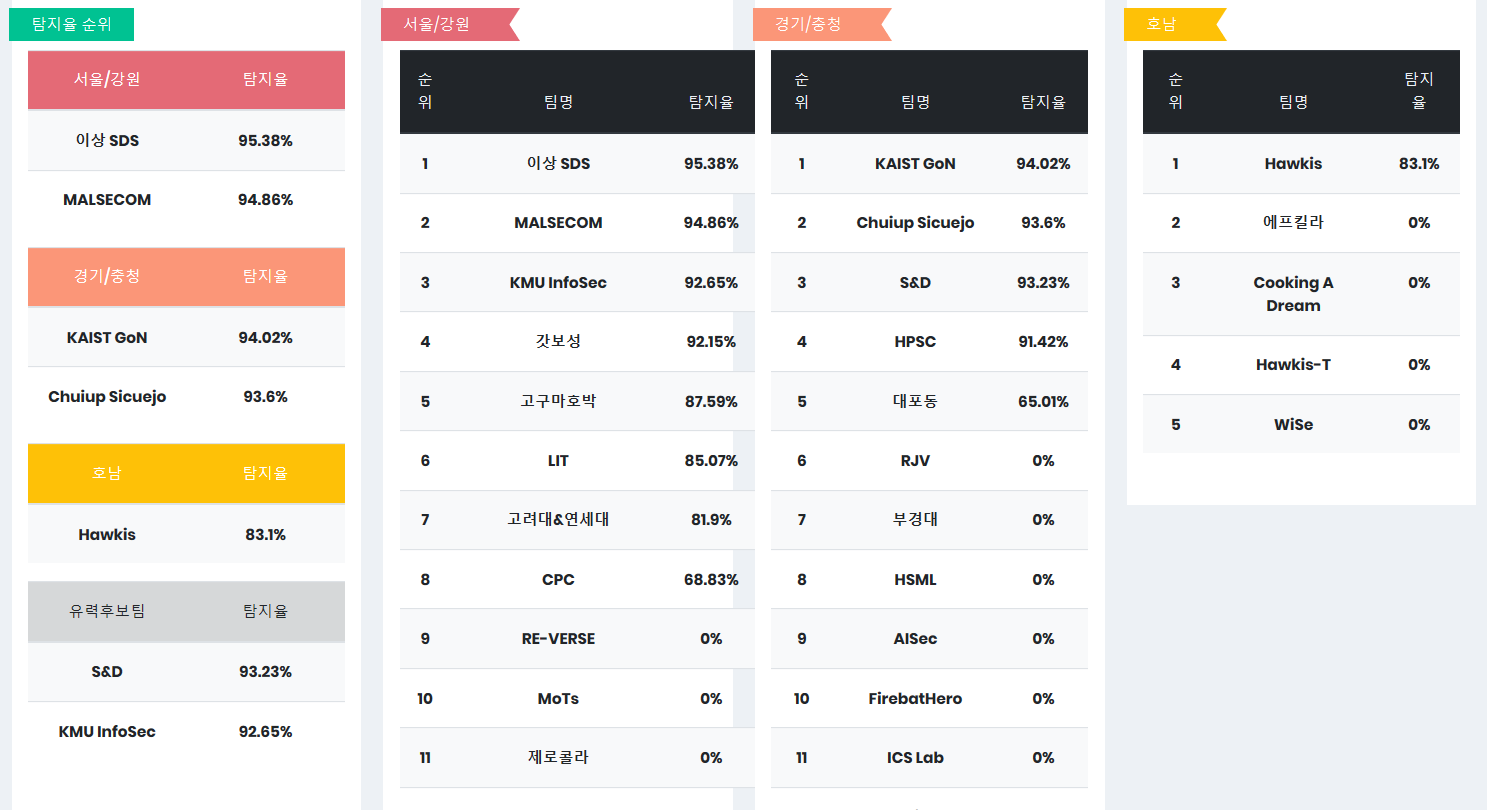
AI기반의 머신러닝기법을 활용한 악성코드 탐지 방법 - 정적분석
최영호
상명대학교(천안) 정보보안공학과
Ⅰ 서론
악성파일 내의 존재하는 유니코드(Unicode)나 아스키형태(ASCII)로 이루어져 있는 문자(String)가 유의미하지 않을까 하여 분석을 시도하였다. python을 사용하여 유니코드와 아스키 포맷방식의 문자열 feature를 추출하였고, 단어 임베딩 방법 중 하나인 Doc2Vec를 사용하여 벡터화 시켰다. 벡터화 시킨 모델을 t-sne을 이용해 2차원 나타낸 그림을 통해 연관성을 찾아내었다.
그 결과 API TrainData 파일 1만개 중, 동적 분석을 통해 나온 소프트웨어 3000개, 악성코드 7000개로 총 1만개의 string feature에 대하여 87.59%의 탐지율이 나왔다.
Ⅱ. 악성코드 분석 및 특성 추출
2.1. 데이터셋 분석
주어진 데이터셋이 32bit 윈도우 환경에서 실행이 가능하다고 하여, PE형태의 파일이라는 생각으로 가장 먼저 정적 분석을 하기 위하여 python 기반의 peframe분석도구를 이용하여 분석을 시도해 보았다. 여기서 PE 파일이란 Portable Executable File의 약자로 실행 가능한 파일을 의미한다.
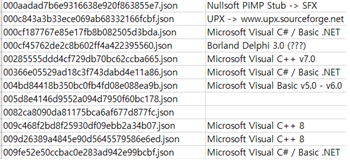
많은 파일들이 UPX나 MSLRH, ACProtect 등 다양한 종류의 패커로 패킹되어 있었고, 몇몇 파일들은 정적분석 데이터가 아주 희박하여 feature 추출에 어려움이 있었다. 또한 언패킹 툴 들을 이용하기에는 1만개의 데이터 전부를 적절하게 언패킹하기에는 힘들다고 판단하였다.
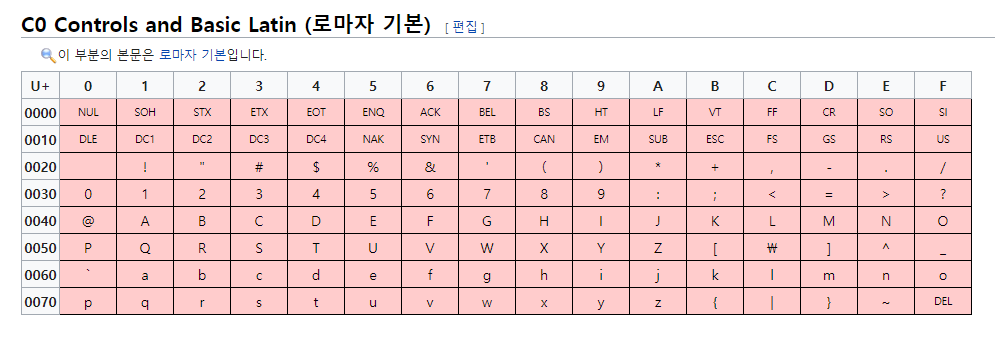
그림 출처: 유니코드_0000~0FFF#C0_Controls_and_Basic_Latin_(로마자_기본)
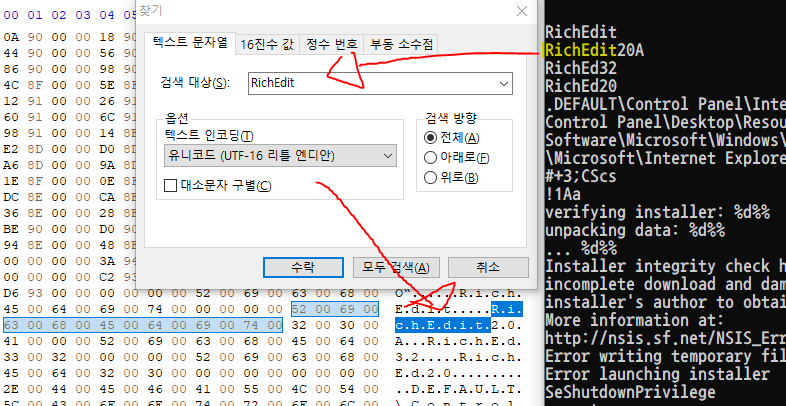
유니코드 문자 인코딩 방식중 하나인 UTF-16으로 데이터를 저장할 때 2~4byte로 가변적으로 저장하는데, HexEditor를 열어 'R'을 살펴보면 리틀엔디안으로 읽었을때 2byte를 차지하는 유니코드 '0x00 52' 으로 볼 수 있다.
이를 유니코드 표(로마자 기본)에서 살펴보면 'R'을 의미하는 것을 볼 수 있다.
이처럼 파일에 들어있는 유니코드 형태의 string 데이터를 추출하여 feature셋으로 만들어보고자 한다. 물론 패킹되어 있기때문에 제대로 된 특징을 찾아내기가 힘들 수도 있으나, 몇몇개의 파일을 분석 해보았을 때 위와 같이 유의미해보이는 문자들을 발견하였다.
2.2. 정상/악성코드 탐지(판단) 결과
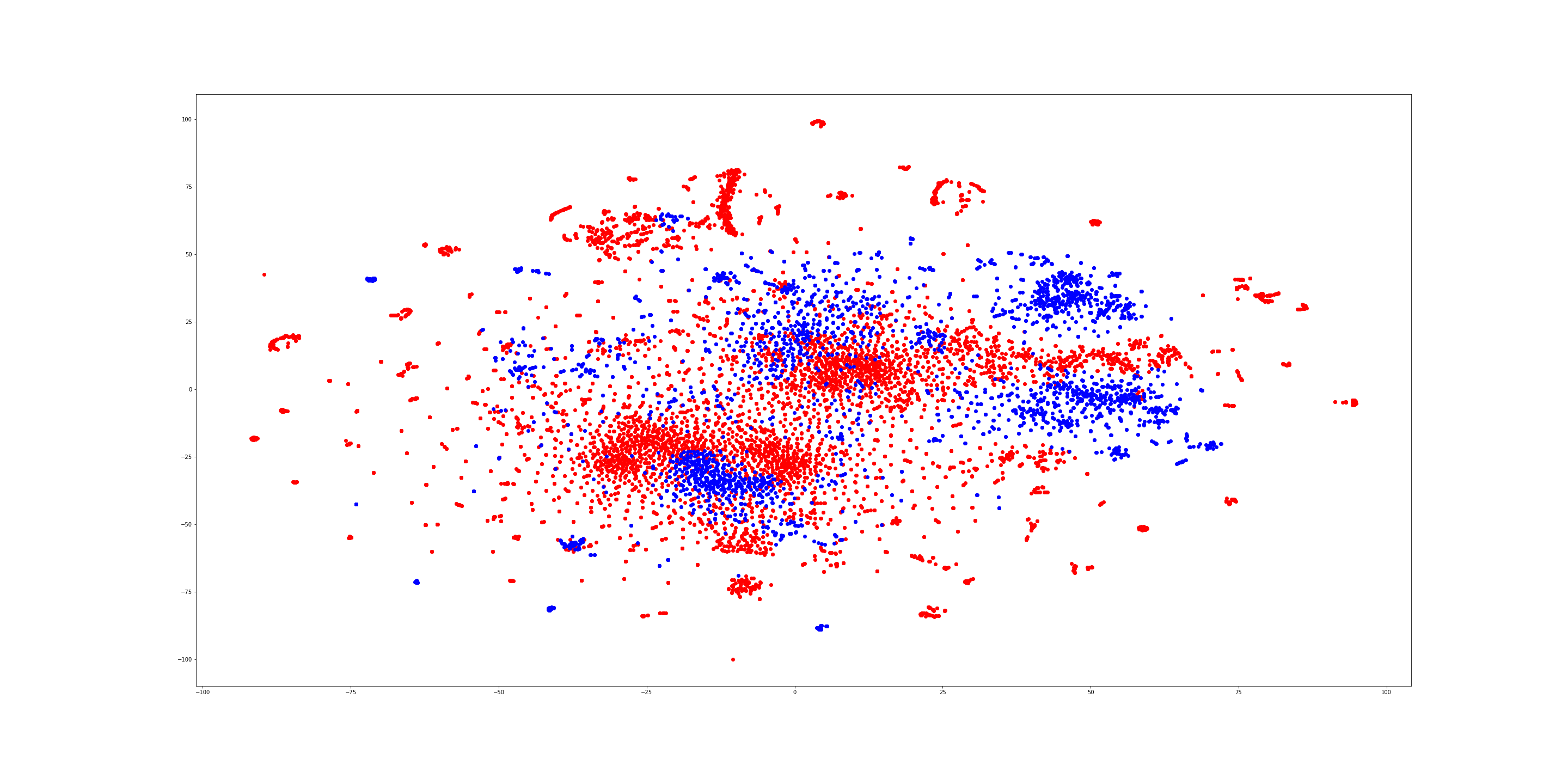
Doc2vec는 문서의 유사도를 벡터로 나타내는데 수 있는데 여기서는 유니코드 형태의 string 시퀀스들을 하나의 문서로 생각하고 악성코드와 정상파일을 학습시킨 뒤 t-sne를 통해 2차원으로 차원 압축을 시켜 데이터를 시각화 해보았다.
doc2vec 옵션
vector_size=100, alpha=0.025, min_alpha=0.025, min_count=100, window = 50, dm =1그림과 같이 일부 섞여 있긴 하지만 파랑색 도트(소프트웨어), 빨강색 도트(악성코드)가 소,대규모로 군집를 이루고 있음을 볼 수 있다. 이를 통해 유니코드형태의 string 시퀀스를 악성행위와 일반 파일을 구분하는 feature로 충분히 사용 할 수 있을거라 판단하였다.
2.3. 특성 추출
https://technet.microsoft.com/en-us/sysinternals/strings.aspx 에서 제공하는 string 실행파일을 사용하였다.
-u 옵션을 사용하여 유니코드 형태 또는 아스키형태의 스트링 파일만 추출하여 각 소프트웨어, 악성코드 별로 리스트를 생성하여 CSV 파일로 저장하였다.
2.4. 특성 분류결과
모든 string의 종류를 세본결과 약 8만개 이상의 종류의 string 종류가 나왔다. Windows 및 최소 문자 파라미터를 조절하여 속도 향상과 분류의 정확도를 늘려야한다고 생각한다.
Ⅲ. 탐지 알고리즘 구성
3.1. String set 생성

가장 먼저 string 소프트웨어를 이용하여 파일들의 유니코드 string 시퀀스를 추출을 한다. 파일크기가 크기 때문에 추출 후 별도의 csv 파일을 생성하여 저장한다.
3.2. Doc2vec 모델 생성
Doc2vec 모델은 문서를 벡터화 시킬 때 사용한다. 여기서는 동적 API 시퀀스를 일종의 문서로 생각하고 Doc2vec 모델의 파라미터 값을 다르게 시도하며 학습시켰다.
3.3. Xgboost 학습 전 학습데이터 전처리
생성한 Doc2vec 모델 중 가장 분류가 잘 된 모델을 토대로 기존의 추출된 API 시퀀스를 벡터로 변경시켜 벡터화한 데이터를 준비한다.
3.4. bayesian-opimization를 활용한 튜닝
bayesian-opimization의 BayesianOptimization을 활용하여 xgboost의 튜닝값을 조절 하였다.
BayesianOptimization를 위한 파라미터
변형값 (최소, 최대)
'numRounds': (1000,2000),
'eta': (0.03, 0.1),
'gamma': (0, 10),
'maxDepth': (4, 10),
'minChildWeight': (0, 10),
'subsample': (0, 1),
'colSample': (0, 1)
고정된 값으로 xgb의 주요 파라미터로는 아래와 같이 고정시켰다.
"objective": "reg:linear",
"booster" : "gbtree",
"eval_metric": "mae",
"tree_method": 'auto',
[소스코드 출처]
http://codingwiththomas.blogspot.com/2016/10/xgboost-bayesian-hyperparameter-tuning.html
다음 소스를 일부 수정하여, 적용하였다.
Ⅳ. 실험
4.4. 실험 환경
분석을 위해 사용한 가상머신은 ubuntu 16.04LTS 버전을 사용하였고, 정적 분석 ubuntu 16.04LTS 을 위해 PEframe 5.0.1및 python 2.7.3을 이용해 추출하였다.
Strgins 추출 및 분석은 https://technet.microsoft.com/en-us/sysinternals/strings.aspx 에서 제공하는 string 실행파일을 사용하였으며, python3.6.5를 사용하여 strgin실행파일의 데이터를 CSV 파일로 저장하였다.
Doc2vec분석은 윈도우10에서 진행하였으며, python3.6.5에 gensim 3.6.0 패키지를 사용하여 실험하였다.
학습을 위한 xgboost 0.80 를 사용하였고, xgboost를 사용하여 최적의 튜닝 값을 계산을 위해 bayesian-opimization 0.6 를 사용하였다.
Ⅴ. 평가
테스트를 위해 Doc2vec를 tsene로 변경했을 때 어느정도 악성코드와 소프트웨어가 구분이된다고 생각하는 모델을 하나 선정하였다.
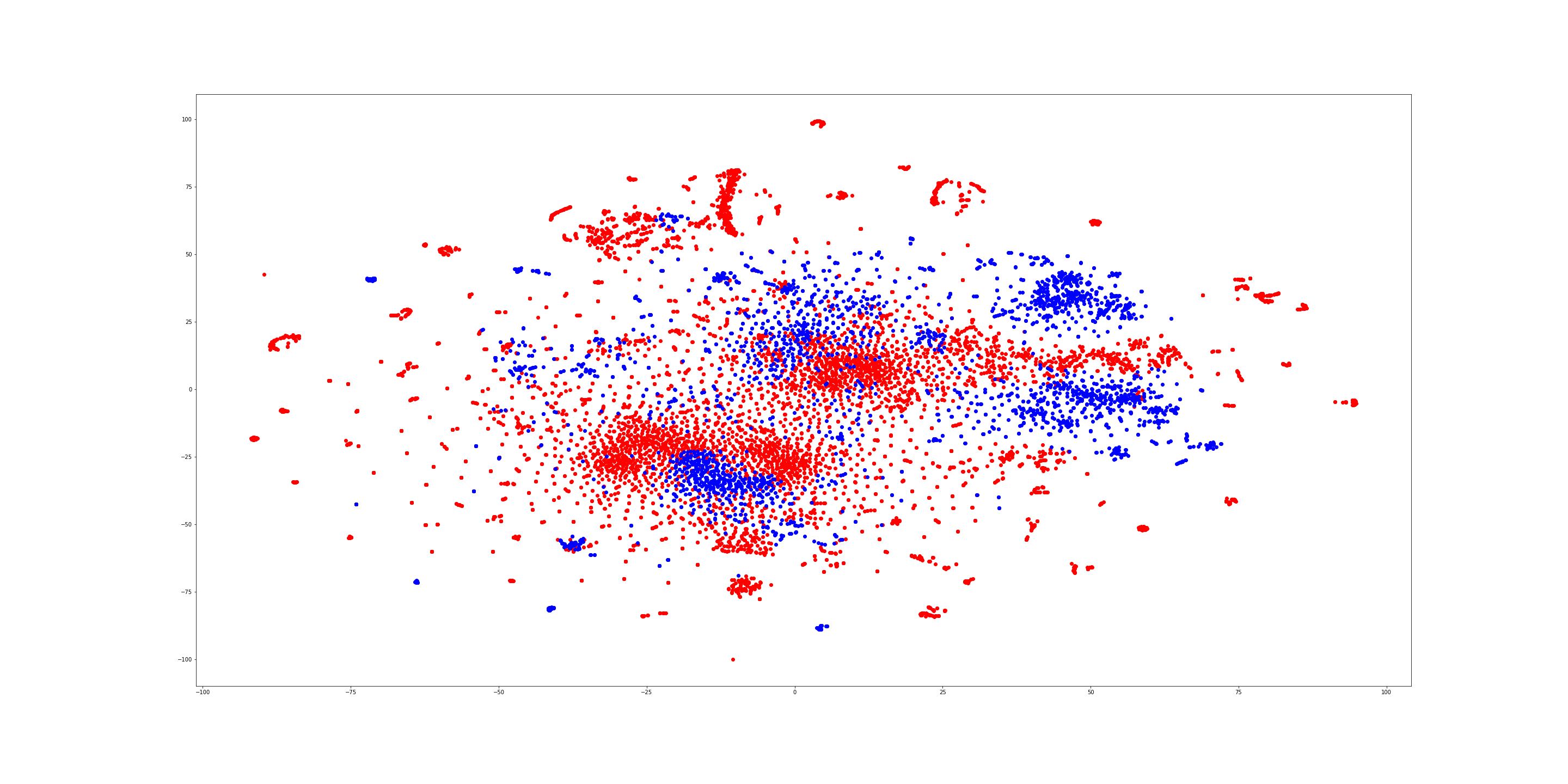
mincount = 100, window = 50 ,vector_size = 100평가에 사용된 모델을 T-SNE로 나타낸 것으로 학습시킨 파라미터 값은 다음과 같다.
당시 대회에 제출한 정확도가 87.59% 나온 Xgboost 파라미터
0.22587
numRounds: 1720
{'eta': 0.03,
'max_depth': 10,
'subsample': 1.0,
'objective': 'reg:linear',
'silent': 1,
'min_child_weight': 10,
'gamma': 0.0,
'booster': 'gbtree',
'eval_metric': 'mae',
'tree_method': 'auto',
'scale_pos_weight': 0.48
}최적화된 학습 파라미터를 이용하여 xgboost를 학습 시킨 후 결과로 약 87.59%의 정확도가 나왔다.
Ⅵ. 결론
유니코드 string 데이터 셋만으로는 100퍼에 근접한 모델은 내기 어렵다고 생각한다. 다른 feature들과 함께 특징 추출을 한다면 좀 더 나은 모델이 될 것이다. 또한 이러한 유니코드 String방식의 추출에 대하여 통계학적 근거를 명확하게 증명하지 못하였다.
그러나 추출한 특징이 많이 빈약한 것에 비해 정확도가 높게 나온 것으로 봐서 Xgboost와 bayesian-opimization를 활용한 모델의 적절한 튜닝값을 찾은 것이 크게 영향을 미쳤다고 본다.
[참고문헌]
[1] 임태원, "실행파일 이미지화와 Word2Vec 을 이용한 딥러닝 기반 악성코드 탐지방법에 대한 연구," (학위논문(석사), 성균관대학교 정보통신대학원 : 정보보호학과 2017. 8 , n.d.), 1-55.
'프로젝트 > 악성코드 분석' 카테고리의 다른 글
| AI기반의 머신러닝기법을 활용한 악성코드 탐지 방법 - 동적분석 (1) | 2020.01.31 |
|---|
